
Before You Continue:
If you’re new to the concept of State of Charge (SoC) and how it can be estimated using different models like CNN, GRU, and TCN, I recommend reading this blog. It gives a clear explanation of what SoC is and how these models work together.
Time-series forecasting has become increasingly important in various fields, including finance, healthcare, and energy management. Traditional methods often struggle with capturing complex temporal patterns. Recently, the combination of Temporal Convolutional Networks (TCNs) and Transformers has shown promising results in handling sequential data. This blog will delve deep into both architectures, their mathematical foundations, and why their combination can enhance forecasting performance.
A TCN consists of dilated, causal 1D convolutional layers with the same input and output lengths. The following sections go into detail about what these terms actually mean.
Causal 1D Convolution
A causal convolution ensures that the output at time step 𝑡tis influenced only by inputs from time steps 𝑡tand earlier. This prevents the model from using future information to predict past events, which is essential for time-series data that must respect temporal order.
In causal convolution, for each position in the sequence, the output depends solely on the current and past time steps, similar to how a recurrent neural network (RNN) processes data sequentially. However, TCNs can process the entire sequence in parallel while preserving causality.
Consider a simple 1D convolutional layer with a kernel size 𝑘k. In standard convolution, the kernel can access both past and future values around each time step. In contrast, causal convolution restricts the kernel to the current and past values.
A 1D convolutional layer takes an input tensor with the shape (𝑏𝑎𝑡𝑐ℎ_𝑠𝑖𝑧𝑒,𝑖𝑛𝑝𝑢𝑡_𝑙𝑒𝑛𝑔𝑡ℎ,𝑛𝑟_𝑖𝑛𝑝𝑢𝑡_𝑐ℎ𝑎𝑛𝑛𝑒𝑙𝑠) and outputs a tensor of shape (𝑏𝑎𝑡𝑐ℎ_𝑠𝑖𝑧𝑒,𝑖𝑛𝑝𝑢𝑡_𝑙𝑒𝑛𝑔𝑡ℎ,𝑛𝑟_𝑜𝑢𝑡𝑝𝑢𝑡_𝑐ℎ𝑎𝑛𝑛𝑒𝑙𝑠).
This process occurs for every element in the batch, but for simplicity, let’s consider one element. The input tensor has three dimensions: 𝑏𝑎𝑡𝑐ℎ_𝑠𝑖𝑧𝑒(the number of sequences processed at once), 𝑖𝑛𝑝𝑢𝑡_𝑙𝑒𝑛𝑔𝑡ℎ(the length of each sequence), and 𝑛𝑟_𝑖𝑛𝑝𝑢𝑡_𝑐ℎ𝑎𝑛𝑛𝑒𝑙𝑠(the number of features at each time step, such as voltage, temperature, and current). The output tensor retains the same shape for 𝑏𝑎𝑡𝑐ℎ_𝑠𝑖𝑧𝑒 𝑎𝑛𝑑 𝑖𝑛𝑝𝑢𝑡_𝑙𝑒𝑛𝑔𝑡ℎ, but differs in 𝑛𝑟_𝑜𝑢𝑡𝑝𝑢𝑡_𝑐ℎ𝑎𝑛𝑛𝑒𝑙𝑠.
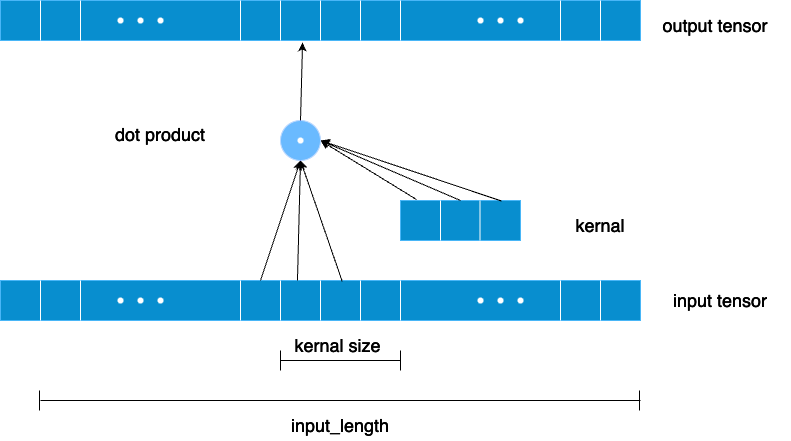
If the input to the causal convolution layer has shape (B,T,𝐶𝑖𝑛Cin)
Where:
1. \( B \): Batch size
2. \( T \): Input sequence length
3. \( C_{\text{in}} \): Number of input channels (features)the causal convolution will ensure that for each time step 𝑡t, the output at 𝑡t only depends on 𝐼𝑛𝑝𝑢𝑡[𝑡−𝑘+1,𝑡] So, the output at 𝑡t will not be influenced by any future time steps beyond 𝑡t
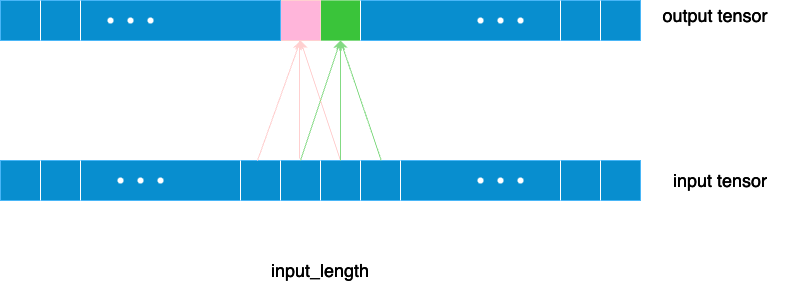
For a causal convolution with kernel size k, the output at time t is given by :
$$\text{Output}[t] = \sum_{i=0}^{k-1} \text{Input}[t-i] \cdot \text{kernel}[i]$$This ensures that the output at time step t only depends on the values of the input sequence from t back to t−k+1.
Example: Causal Padding
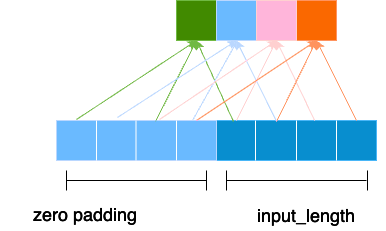
To ensure that the output sequence has the same length as the input sequence (i.e., 𝑇𝑜𝑢𝑡𝑝𝑢𝑡=𝑇𝑖𝑛𝑝𝑢𝑡), causal padding is applied. This adds zeros to the beginning of the input sequence, so that the first output value has access to the required k−1past values.
For a kernel size k=3, if the input sequence is:
$$\text{Input} = [x_1, x_2, x_3, x_4, \ldots]$$The padded input for causal convolution would be:
$$\text{Padded Input} = [0, 0, x_1, x_2, x_3, \ldots]$$With causal padding, the first output value will depend only on x1 the second on x1,x2 and so on, ensuring causality.
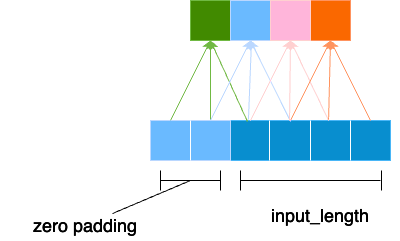
Dilation
In TCN the dilated convolution layer plays a critical role in capturing long-range dependencies in sequential data while maintaining computational efficiency. Dilated convolution expands the receptive field of the network exponentially without increasing the number of parameters or layers. This means that the network can look at a wider context in the input sequence with fewer layers, making it more effective for tasks where information from the distant past (in a time series) is important for making predictions.
In a standard 1D convolution, each filter (or kernel) looks at a fixed window of neighbouring points. For example, if the kernel size is 3, the filter would only look at three adjacent points at a time. However, in a dilated convolution, the filter looks at points that are spaced apart by a certain dilation factor. The dilation factor determines the distance between the points that the kernel will consider, effectively widening the receptive field.
Let’s define the key components:
1. Dilation factor (d): This is the spacing between the elements in the input sequence that the kernel uses to calculate the output. A dilation factor of 1 results in a standard convolution, where the kernel considers consecutive elements. A dilation factor of 2 means the kernel skips one element between each point, and so on.
2. Receptive field: This refers to how much of the input sequence the network can see or "attend to" at each layer. As the dilation factor increases, the receptive field grows exponentially, allowing the network to take into account broader temporal information from the input sequence.
The output of a dilated convolution can be described by the following equation:
$$y(t) = \sum_{i=0}^{k-1} x(t - i \cdot d) \cdot w(i) y(t)$$Where:
1. \( y(t) \): Output at time step \( t \)
2. \( x(t) \): Input at time step \( t \)
3. \( w(i) \): Weight of the kernel at position \( i \)
4. \( k \): Kernel size
5. \( d \): Dilation factorAs the dilation factor increases, the convolution skips more points in the input sequence. For example, with a kernel size of 3 and a dilation factor of 2, the kernel will operate on every second point in the input sequence (e.g., points 1, 3, and 5 instead of 1, 2, and 3).
Example
Suppose we have an input sequence of 8 time steps, and we are using a kernel size of 3. In a standard 1D convolution, the kernel would look at three consecutive points, such as steps 1, 2, and 3. But with a dilation factor of 2, the kernel would instead look at steps 1, 3, and 5. As a result, the network can capture information from non-adjacent points in the sequence, which is particularly useful when long-term dependencies need to be modelled.
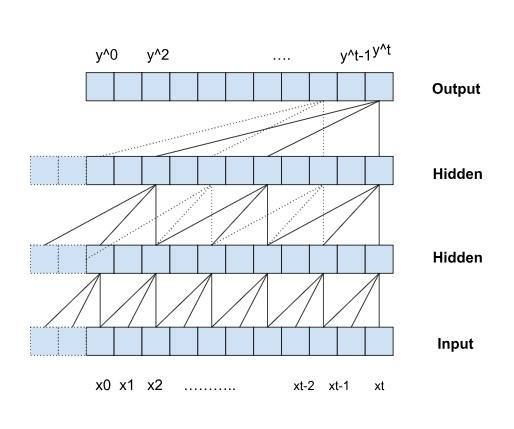
In TCNs, dilated convolutions are applied in a way that each layer captures information from progressively larger parts of the input sequence. At each subsequent layer, the dilation factor is typically doubled. For instance, the first layer may use a dilation factor of 1, the second layer a factor of 2, and the third layer a factor of 4. This exponential growth allows the network to effectively model long-term dependencies in a time series, while still focusing on local patterns in the data.
Transformer
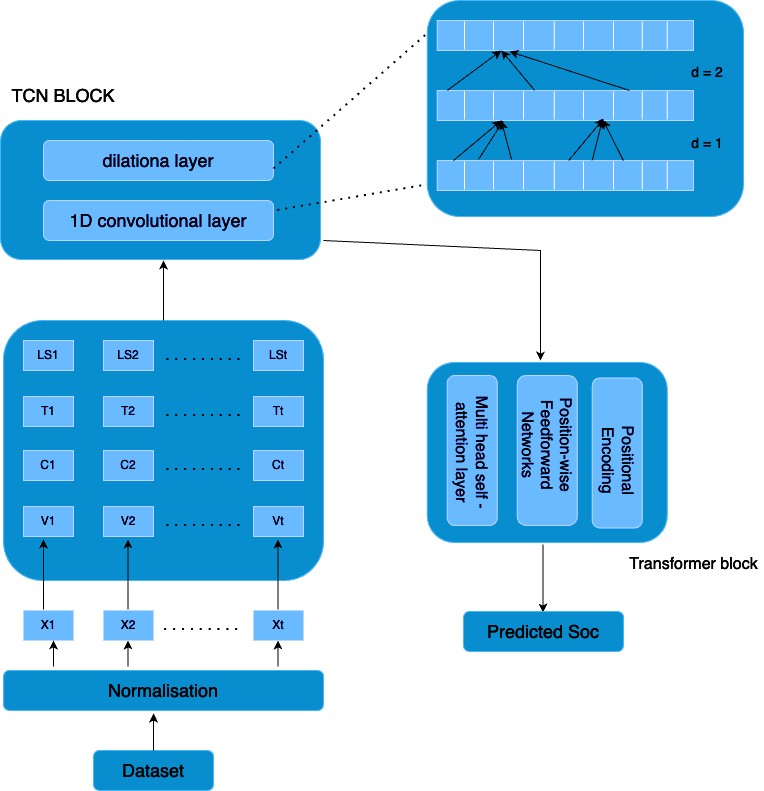
The output of the TCN can be fed as input to the Transformer for further processing. TCN, through its use of dilated convolutions, can capture both local and long-term temporal dependencies efficiently, while Transformers complement this by enhancing the modeling of complex, long-range dependencies through their self-attention mechanism. This combination leverages the strengths of both architectures: TCN's ability to capture patterns across varying time scales and the Transformer's capacity to focus on the most relevant parts of the sequence through attention.
The TCN processes the sequential data (such as voltage, current, temperature, and previous SOC values) and outputs a tensor that captures the relevant temporal patterns. The TCN's output tensor would have the shape:
$$(\text{batch\_size}, \text{sequence\_length}, \text{num\_features})$$Where:
1. \( \text{batch\_size} \): Number of sequences processed at once
2. \( \text{sequence\_length} \): Length of the input time series (e.g., the number of past time steps considered)
3. \( \text{num\_features} \): Number of output channels from the last TCN layer, which represents the learned featuresThe output tensor from the TCN is then passed as input to the Transformer model. Each time step (with its respective features) from the TCN acts as an input token for the Transformer. The input to the Transformer is thus a sequence of vectors, where each vector represents the extracted features of the system's state (SOC, voltage, current, etc.) over a specific time step.
Transformer Architecture
The Transformer is built around the self-attention mechanism, which allows the model to focus on different parts of the input sequence to compute more accurate predictions. It consists of two main components: the encoder and the decoder. For SOC estimation, we typically focus on the encoder portion to process the sequential data.
Transformer Encoder
The Transformer encoder processes input sequences and generates high-level representations using a series of stacked layers, each composed of:
1. Multi-Head Self-Attention: The self-attention mechanism allows the Transformer to learn dependencies between all time steps in the sequence, regardless of distance. This is particularly important for SOC estimation, where distant past time steps (such as voltage or current changes) might influence the current SOC.
The attention mechanism works as follows:
1. Each input vector (time step's features) is transformed into three vectors: query (Q), key (K), and value (V).
2. The attention score between two time steps is computed by taking the dot product of their query and key vectors. The resulting score is used to weight the value vectors, producing an output that emphasizes important time steps while diminishing less relevant ones.
The self-attention operation for one time step iii is given by:
$$\text{Attention}(Q_i, K_j, V_j) = \text{softmax}\left(\frac{Q_i \cdot K_j}{\sqrt{d_k}}\right) \cdot V_j$$Where:
1. \( Q_i, K_j, \) and \( V_j \): Query, key, and value vectors of time steps \( i \) and \( j \)
2. \( d_k \): Dimensionality of the key vectorsMultiple attention heads are used to capture different patterns and relationships within the data.
1. Position-wise Feedforward Networks: After the attention mechanism, each time step is passed through a feedforward neural network. This helps in capturing non-linear relationships and refining the learned representations.
2. Since Transformers are inherently permutation-invariant, positional encodings are added to the input to indicate the order of the time steps in the sequence. This ensures that the Transformer knows the relative position of each time step, which is crucial for sequence-based tasks like SOC estimation.
Each of these operations is repeated across several layers, allowing the Transformer to progressively refine the input and capture complex patterns in the data.
1. The model is trained for 20 epochs. Each epoch involves going through the entire training dataset once, adjusting the model’s weights to reduce prediction errors.
2. Used batches of data instead of processing the entire dataset at once. This code uses a batch size of 64, meaning the model processes 64 data samples at a time, which helps balance computation efficiency and memory usage.
3. The Transformer part of the model uses 4 heads in its multi-head attention mechanism. This allows the model to look at the data from multiple perspectives during training, improving its ability to capture complex relationships in the data.
4. The Transformer consists of 2 encoder layers and 2 decoder layers, which help the model capture both short-term and long-term dependencies in the data.
5. The learning rate for the Adam optimizer is set to 0.001, which controls how quickly the model adjusts its weights based on the loss. A lower learning rate makes the model learn more slowly and steadily, avoiding large changes that might destabilize training.
6. The RMSE values fluctuate between 0.4 and 0.7 during validation, which is expected as the model learns and improves over time. The final RMSE values reflect the model’s accuracy in predicting SOC values close to the actual values. RMSE provides a clear metric to see how well the model performs during both training and validation phases.
Frequently Asked Questions:
1. What is State of Charge (SoC) in batteries?
SoC tells us how much charge is left in a battery compared to its full capacity. It’s like a “fuel gauge” for batteries, helping manage energy systems efficiently.
2. Why is SoC estimation important?
Accurate SoC estimation helps improve battery safety, extend lifespan, and optimize energy usage in applications like electric vehicles and renewable energy storage.
3. How does a Temporal Convolutional Network (TCN) work?
A TCN uses special 1D convolutions that look only at current and past data (not future values). With techniques like causal padding and dilation, TCNs can capture both short-term and long-term patterns in time-series data.
4. What is the role of causal convolution in TCNs?
Causal convolution ensures the model respects time order meaning predictions at time t only depend on inputs from time t and earlier, never from the future.